August 06, 2024 by Houssem Eddine Zerrad
GraphQL is a query language for APIs, developed by Facebook in 2012 and released to the public in 2015. It allows clients to request exactly the data they need, making it more efficient and flexible compared to traditional REST APIs.
The schema defines the structure of the API, including types, queries, and mutations. It serves as a contract between the client and the server, specifying what types of data can be queried or mutated. The schema is written in the GraphQL Schema Definition Language (SDL).
Example:
type User { id: ID! name: String! email: String! } type Query { getUser(id: ID!): User } type Mutation { createUser(name: String!, email: String!): User }
In this example, the User type has three fields: id, name, and email. The Query type defines a single query, getUser, which takes an id argument and returns a User. The Mutation type defines a single mutation, createUser, which takes name and email arguments and returns a User.
Queries are used to read or fetch values. They allow clients to request specific data from the server.
query { getUser(id: "1") { id name email } }
In this query, the client requests the id, name, and email fields of the User with the ID of "1". The server responds with the requested data.
Mutations are used to write or post values. They allow clients to modify data on the server.
mutation { createUser(name: "John Doe", email: "john@example.com") { id name email } }
In this mutation, the client creates a new User with the name "John Doe" and email "john@example.com". The server responds with the id, name, and email of the newly created User.
Resolvers are functions that populate the data for individual fields in the schema. Each field in the schema has a corresponding resolver function that retrieves or computes the data for that field.
const resolvers = { Query: { getUser: (parent, args, context, info) => { // Fetch user from database using args.id return users.find(user => user.id === args.id); } }, Mutation: { createUser: (parent, args, context, info) => { // Create a new user in the database const newUser = { id: generateId(), name: args.name, email: args.email }; users.push(newUser); return newUser; } } };
In this example, the getUser resolver resolves getUser GraphQL query by fetching a user by ID from the database. In the same fashion, createUser resolves createUser GraphQL mutation by creating a new user in the database.
Subscriptions are a way to push real-time updates from the server to the client. They are typically used to notify clients of changes to data, such as new messages in a chat application or updates to a user's status.
type Subscription { userCreated: User }
In this example, the Subscription type defines a single subscription, userCreated, which returns a User.
Subscription Resolver:
const { PubSub } = require('graphql-subscriptions'); const pubsub = new PubSub(); const resolvers = { Query: { getUser: (parent, args, context, info) => { return users.find(user => user.id === args.id); } }, Mutation: { createUser: (parent, args, context, info) => { const newUser = { id: generateId(), name: args.name, email: args.email }; users.push(newUser); pubsub.publish('USER_CREATED', { userCreated: newUser }); return newUser; } }, Subscription: { userCreated: { subscribe: () => pubsub.asyncIterator(['USER_CREATED']) } } };
In this example, when a new user is created using the createUser mutation, the userCreated event is published using the PubSub instance. Clients subscribed to the userCreated subscription will receive the new user data in real-time.
Client-side Subscription:
import { gql, useSubscription } from '@apollo/client'; const USER_CREATED = gql` subscription { userCreated { id name email } } `; function UserCreatedSubscription() { const { data, loading, error } = useSubscription(USER_CREATED); if (loading) return <p>Loading...</p>; if (error) return <p>Error: {error.message}</p>; return ( <div> <h3>New User Created:</h3> <p>ID: {data.userCreated.id}</p> <p>Name: {data.userCreated.name}</p> <p>Email: {data.userCreated.email}</p> </div> ); }
In this client-side example, the useSubscription hook from Apollo Client is used to subscribe to the userCreated subscription. When a new user is created, the component will render the new user's details in real-time.
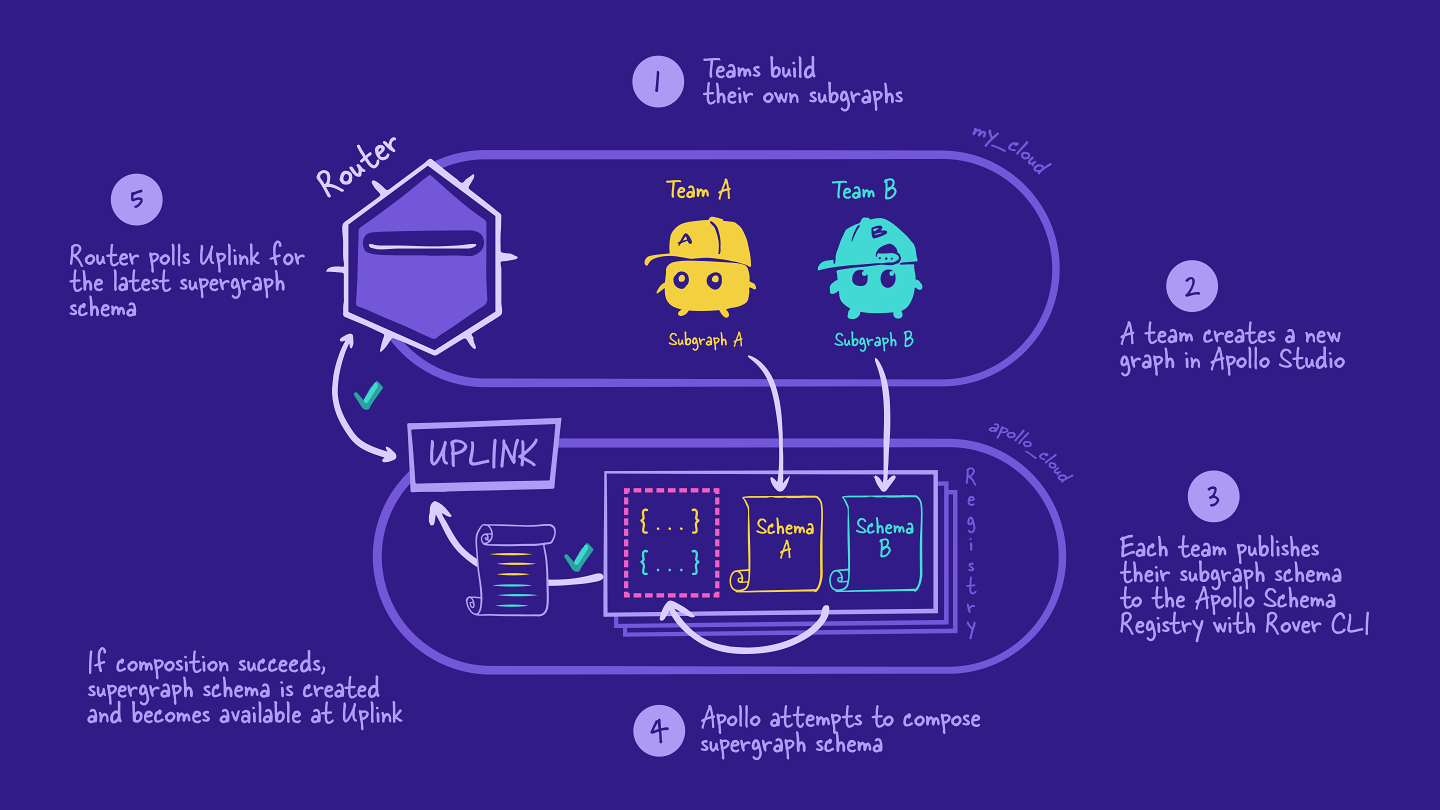
A Supergraph is an architectural paradigm that integrates multiple GraphQL services into a single unified schema. This concept allows developers to manage complex applications more effectively by providing a cohesive interface for querying disparate data sources. The term "Supergraph" was popularized by Apollo GraphQL, which emphasizes its role in simplifying microservices architectures.
Unified Schema: A Supergraph aggregates various sub-schemas from different services into one comprehensive schema. This means clients can query across multiple services without knowing their individual structures.
Federation: One of the core principles behind Supergraphs is federation—the ability to compose multiple GraphQL services into one schema seamlessly. Apollo Federation enables this functionality through directives that define how types are extended across services.
Decoupling Services: By using a Supergraph architecture, teams can work on different microservices independently without affecting the overall system's functionality.
Versioning and Evolution: With a unified schema, managing different versions of your API becomes easier since changes can be made at the service level without disrupting the entire application.
The implementation of a Supergraph typically involves several steps:
Each microservice exposes its own GraphQL schema (subschema). These subschemas define types, queries, and mutations specific to that service. Subschemas are designed to encapsulate the functionality of individual services, allowing for modular and independent development.
Example:
# User Service Schema type User { id: ID! name: String! email: String! } type Query { getUser(id: ID!): User } type Mutation { createUser(name: String!, email: String!): User }
# Product Service Schema type Product { id: ID! name: String! price: Float! } type Query { getProduct(id: ID!): Product } type Mutation { createProduct(name: String!, price: Float!): Product }
In these examples, the User service and Product service each define their own schema, handling user and product data respectively.
A gateway acts as an entry point for client requests. It aggregates all subschemas into one unified schema using tools like Apollo Gateway or Hasura's supergraph capabilities. The gateway handles the composition of subschemas, allowing clients to interact with a single GraphQL endpoint.
Example:
const { ApolloServer } = require('apollo-server'); const { ApolloGateway } = require('@apollo/gateway'); const gateway = new ApolloGateway({ serviceList: [ { name: 'user', url: 'http://localhost:4001' }, { name: 'product', url: 'http://localhost:4002' }, ], }); const server = new ApolloServer({ gateway }); server.listen().then(({ url }) => { console.log(`🚀 Server ready at ${url}`); });
In this example, Apollo Gateway is used to create a unified GraphQL API from the User and Product services.
When a client sends a query to the gateway, it intelligently delegates parts of the query to the appropriate subschemas based on type definitions and resolvers defined within those schemas. The gateway breaks down the query into smaller parts and routes each part to the relevant microservice.
Example Query:
query { getUser(id: "1") { id name email } getProduct(id: "101") { id name price } }
In this query, the gateway routes the getUser query to the User service and the getProduct query to the Product service.
After each service processes its part of the query, results are sent back to the gateway, which aggregates them before returning them to the client in one cohesive response. This ensures that the client receives a single, unified response even though the data may come from multiple microservices.
Example Response:
{ "data": { "getUser": { "id": "1", "name": "John Doe", "email": "john@example.com" }, "getProduct": { "id": "101", "name": "Laptop", "price": 999.99 } } }
In this response, the gateway combines the results from the User and Product services into a single JSON response for the client.
Improved Developer Experience: Developers can focus on building individual services without worrying about how they fit into other parts of the application.
Scalability: As your application grows, adding new features or services becomes simpler since they can be integrated into the existing Supergraph with minimal friction.
Performance Optimization: By reducing over-fetching and under-fetching through precise queries across multiple sources, performance improves significantly compared to traditional REST endpoints.
Flexibility: Organizations can adopt new technologies or frameworks for specific microservices without disrupting existing functionalities within their ecosystem.
Several companies have adopted Supergraphs in various capacities:
Apollo's Implementation: Apollo has successfully implemented federated schemas across numerous projects allowing teams to collaborate efficiently while maintaining autonomy over their respective domains.
Hasura's Approach: Hasura V3 provides built-in support for creating supergraphs with its instant GraphQL APIs on top of databases while allowing developers to extend functionality with custom resolvers when necessary.
Community Contributions: The GitHub repository for Supergraphql showcases community-driven efforts towards building tools and frameworks that facilitate working with supergraphs effectively.
While adopting a Supergraph architecture offers numerous benefits, there are challenges worth noting:
Complexity Management: As you integrate more services into your supergraph, managing dependencies and interactions between them can become complex.
Performance Overhead: The gateway must efficiently handle routing queries and aggregating responses from potentially many microservices; improper configuration may lead to latency issues.
Monitoring and Debugging: With increased complexity comes challenges in monitoring performance metrics and debugging issues that span multiple subschemas.
The introduction of Supergraphs marks an exciting evolution in how developers architect their applications using GraphQL technology. By providing a unified way to interact with various data sources while promoting scalability and flexibility within development teams, supergraphs enable organizations to meet modern demands effectively.
As you consider implementing this architectural pattern in your projects, it's crucial to evaluate both its advantages and challenges carefully—ensuring it aligns with your team's goals and technical expertise will pave the way for successful adoption.
Whether you're just starting with GraphQL or looking to enhance your existing architecture with advanced capabilities like supergraphs—embracing this paradigm could very well be your next strategic move towards building robust applications capable of thriving in today's ever-changing landscape.